
Current LLM inference infrastructure is extremely computationally expensive. For a moderate size model, such as LLama 13B, even with the best hardware such as a Nvidia A100, the model can only serve up less than 1 requests per second. This type of speed means some sort of accelerator is necessary in order to speed up request times.
Currently in an A100, 65% of the hardware memory is used for the weights, which are static. Another close to 30% of memory is used to store the dynamic states of the requests for the model.
The task of this accelerator known as “vLLM” is to better use the memory for dynamic states, so that memory is not wasted on requests. This is because when a prompt is given to an LLM, we do not know how long the token sequence will be generated (it is usually capped at 2048 tokens). This reserved memory not used is called “internal fragmentation” and is simply wasted memory.
Additionally, when memory is constantly fragmented and spread out we call this external fragmentation because it is still wasting memory.
The key idea behind vLLM’s memory manager is analogous to the virtual memory in operating systems
OS partitions memory into fixed-sized pages and maps user programs’ logical pages to physical pages.
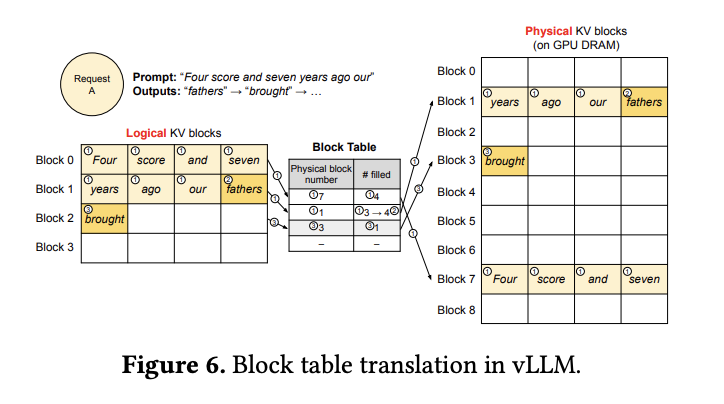
vLLM uses the ideas behind virtual memory to manage the KV cache in an LLM service. Enabled by Page Attention, we organize the KV cache as fixed-size KV blocks, like pages in virtual memory.
Paged Attention blocks allow storing continuous keys and values in non-contiguous memory space which operates on KV cache space. This is done using a block table to map contiguous memory blocks to each other.
Another way vLLM saves memory is by sharing KV blocks if they are the same (with respect to block length which is 4 in the image). This way the reference count can be greatly reduced helping improve memory efficiency.
An example of this is shown in parallel sampling, where users can choose a favorite output from various candidates from a single prompt
vLLM implements a copy-on-write mechanism at the block granularity for the physical blocks that needs modification by multiple sequences, similar to the copy-on-write technique in OS virtual memory. This is done in the reference count as shown in the right top figure.
For the overall results, The study uses two types of sampling (parallel sampling and beach search)
In parallel sampling, all parallel sequences in a request can share the KV cache for the prompt. As shown in the first row of Fig. 14, with a larger number of sequences to sample, vLLM brings more improvement over the Orca baselines
The other sampling is beam search. Since beam search allows for more sharing, vLLM demonstrates even greater performance benefits. The improvement of vLLM over Orca (Oracle) on OPT-13B and the Alpaca dataset goes from 1.3× in basic sampling to 2.3× in beam search with a width of 6.